Задачи обработки естественного языка
Рекуррентные нейронные сети. Архитектуры RNN, GRU, LSTM. Затухание градиента, взрыв градиента. Градиентный клиппинг.
RNN
Люди, читая текст, понимают каждое слово, основываясь на понимании предыдущего слова. Традиционные нейронные сети не обладают этим свойством, и в этом их главный недостаток. Представим, например, что мы хотим классифицировать события, происходящие в фильме. Непонятно, как традиционная нейронная сеть могла бы использовать рассуждения о предыдущих событиях фильма, чтобы получить информацию о последующих.\ Решить эту проблемы помогают рекуррентые нейронные сети (Recurrent Neural Networks, RNN). Это сети, содержащие обратные связи и позволяющие сохранять информацию.
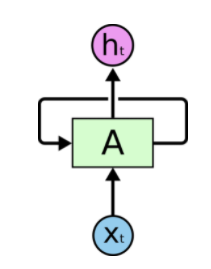
В рекуррентных сетях циклы разрешены. В этом случае выход нейрона может быть подключен к его входу, ко входу всех нейронов в текущем слое, и ко входу любого другого нейрона в другом слое. Рекуррентная сеть хорошо подходит именно для анализа последовательностей потому что у нее есть циклические соединения, через которые поступает информация о том, что было на предыдущем шаге работы сети (память) или даже на нескольких предыдущих шагах. Таким образом, РНС могут анализировать текст не как набор изолированных токенов, а как последовательность.
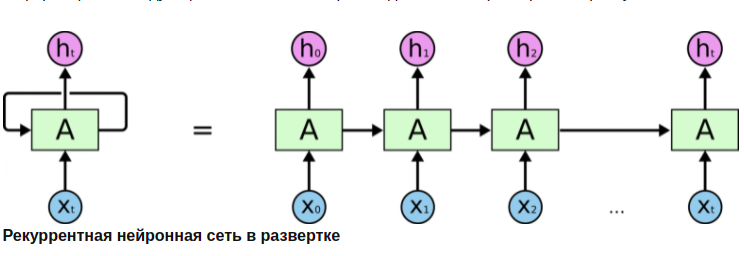
Как работает РНС? Разворачивание по времени:
Рекуррентную сеть можно рассматривать, как несколько копий одной и той же сети, каждая из которых передает информацию последующей копии. На вход копий нейронной сети поступают элементы последовательности. На вход первой копии поступает первый элемент последовательности, на вход второй копии - второй элемент и т.д. пока не дойдем до последней копии. На выходе получаем два значения: выходное (a), и значение h, которое поступает на вход копии сети в следующий момент времени - скрытое состояние, которое учитывает то, что было на предыдущих этапах анализа последовательности. Копия НС в следующий момент времени на сход получает второй элемент последовательности, а также скрытое состояние с предыдущего этапа и анализирует, выдавая снова два значения и т.д., пока не дойдем до последнего элемента данной последовательности. Для него РНС выдает только одно выходное значение без скрытого состояния.\ В отличие от полносвязной НС, РНС может работать с последовательностями входных данных любой длины.
Проблемы рекуррентных сетей:
-
Обучение требует длительного времени
-
Проблема .
-
Ограниченная длительность запоминания предыдущей информации
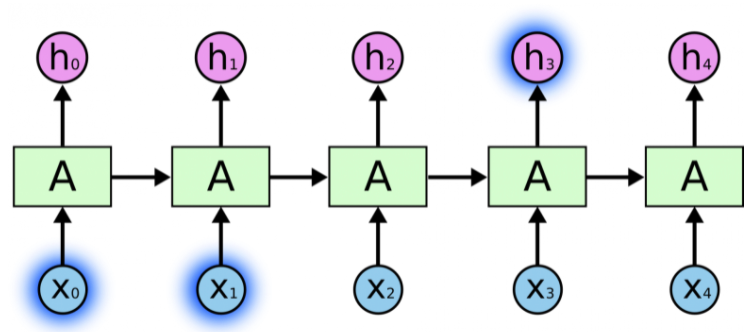
Иногда для выполнения текущей задачи нам необходима только недавняя информация. Рассмотрим, например, языковую модель, пытающуюся предсказать следующее слово на основании предыдущих. Если мы хотим предсказать последнее слово в предложении "облака плывут по небу", нам не нужен более широкий контекст; в этом случае довольно очевидно, что последним словом будет "небу". В этом случае, когда дистанция между актуальной информацией и местом, где она понадобилась, невелика, RNN могут обучиться использованию информации из прошлого.
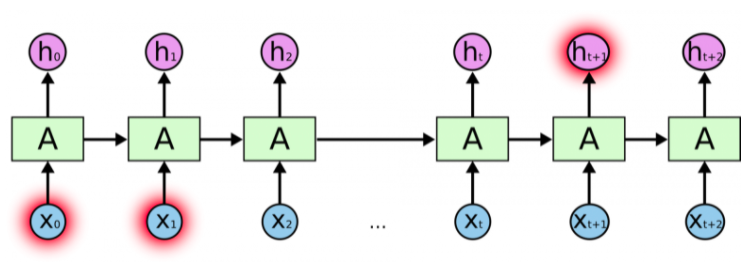
Но бывают случаи, когда нам необходимо больше контекста. Допустим, мы хотим предсказать последнее слово в тексте "Я вырос во Франции \<много текста> Я бегло говорю по-французски". Ближайший контекст (Я бегло говорю) предполагает, что последним словом будет называние языка, но чтобы установить, какого именно языка, нам нужен контекст Франции из более отдаленного прошлого. Таким образом, разрыв между актуальной информацией и точкой ее применения может стать очень большим.\ К сожалению, по мере роста этого расстояния, RNN теряют способность связывать информацию.
LSTM
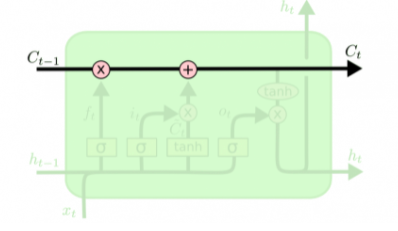
Долгая краткосрочная память (Long short-term memory; LSTM) -- особая разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям. Они прекрасно решают целый ряд разнообразных задач и в настоящее время широко используются.\ Любая рекуррентная нейронная сеть имеет форму цепочки повторяющихся модулей нейронной сети . В обычной RNN структура одного такого модуля очень проста, например, он может представлять собой один слой с функцией активации tanh (гиперболический тангенс) (Рис. 1{reference-type="ref" reference="fig:rnn"}).\
![Повторяющийся модуль в стандартной RNN состоит из одного
слоя.[]{label="fig:rnn"}](../../images/rnn5.png)
Структура LSTM также напоминает цепочку, но модули выглядят иначе. Вместо одного слоя нейронной сети они содержат целых четыре, и эти слои взаимодействуют особенным образом.
![Повторяющийся модуль в LSTM сети состоит из четырех взаимодействующих
слоев.[]{label="fig:LSTM"}](../../images/rnn6.png)
Каждая линия переносит целый вектор от выхода одного узла ко входу другого. Розовыми кружочками обозначены поточечные операции, такие, как сложение векторов, а желтые прямоугольники -- это обученные слои нейронной сети. Сливающиеся линии означают объединение, а разветвляющиеся стрелки говорят о том, что данные копируются и копии уходят в разные компоненты сети.
Основная идея LSTM
Ключевой компонент LSTM -- это состояние ячейки (cell state) -- горизонтальная линия, проходящая по верхней части схемы.\ Состояние ячейки напоминает конвейерную ленту. Она проходит напрямую через всю цепочку, участвуя лишь в нескольких линейных преобразованиях. Информация может легко течь по ней, не подвергаясь изменениям.
Тем не менее, LSTM может удалять информацию из состояния ячейки; этот процесс регулируется структурами, называемыми фильтрами (gates).\ Фильтры позволяют пропускать информацию на основании некоторых условий. Они состоят из слоя сигмоидальной нейронной сети и операции поточечного умножения.
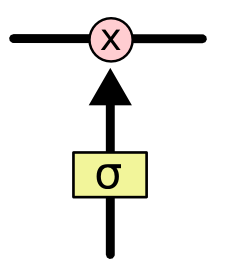
Сигмоидальный слой возвращает числа от нуля до единицы, которые обозначают, какую долю каждого блока информации следует пропустить дальше по сети. Ноль в данном случае означает "не пропускать ничего", единица -- "пропустить все". В LSTM три таких фильтра, позволяющих защищать и контролировать состояние ячейки.
Пошаговый разбор LSTM
Первый шаг в LSTM -- определить, какую информацию можно выбросить из состояния ячейки. Это решение принимает сигмоидальный слой, называемый "слоем фильтра забывания" (forget gate layer). Он смотрит на \(h_{t-1}\) и \(x_t\) и возвращает число от 0 до 1 для каждого числа из состояния ячейки \(C_{t-1}\). 1 означает "полностью сохранить", а 0 -- "полностью выбросить".\ Вернемся к нашему примеру -- языковой модели, предсказывающей следующее слово на основании всех предыдущих. В этом случае состояние ячейки должно сохранить существительного, чтобы затем использовать местоимения соответствующего рода. Когда мы видим новое существительное, мы можем забыть род старого.
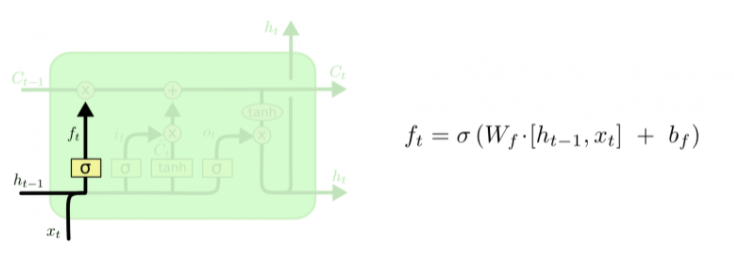
Следующий шаг -- решить, какая новая информация будет храниться в состоянии ячейки. Этот этап состоит из двух частей. Сначала сигмоидальный слой под названием "слой входного фильтра" (input layer gate) определяет, какие значения следует обновить. Затем tanh-слой строит вектор новых значений-кандидатов \(\tilde{C}_t\), которые можно добавить в состояние ячейки.\ В нашем примере с языковой моделью на этом шаге мы хотим добавить род нового существительного, заменив при этом старый.
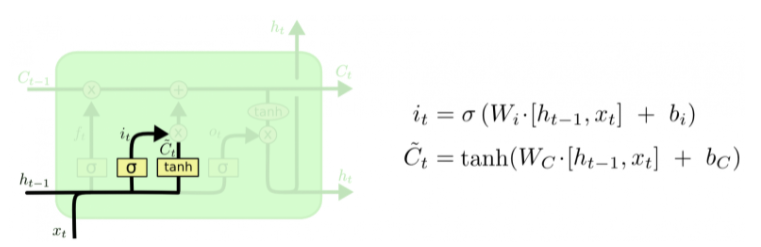
Настало время заменить старое состояние ячейки \(C_{t-1}\) на новое состояние \(C_t\). Что нам нужно делать --- мы уже решили на предыдущих шагах, остается только выполнить это.\ Мы умножаем старое состояние на \(f_t\), забывая то, что мы решили забыть. Затем прибавляем \(i_t*\tilde{C}_t\). Это новые значения-кандидаты, умноженные на \(t\) -- на сколько мы хотим обновить каждое из значений состояния.\ В случае нашей языковой модели это тот момент, когда мы выбрасываем информацию о роде старого существительного и добавляем новую информацию.

Наконец, нужно решить, какую информацию мы хотим получать на выходе. Выходные данные будут основаны на нашем состоянии ячейки, к ним будут применены некоторые фильтры. Сначала мы применяем сигмоидальный слой, который решает, какую информацию из состояния ячейки мы будем выводить. Затем значения состояния ячейки проходят через tanh-слой, чтобы получить на выходе значения из диапазона от -1 до 1, и перемножаются с выходными значениями сигмоидального слоя, что позволяет выводить только требуемую информацию.\ Мы, возможно, захотим, чтобы наша языковая модель, обнаружив существительное, выводила информацию, важную для идущего после него глагола. Например, она может выводить, находится существительное в единственном или множественном числе, чтобы правильно определить форму последующего глагола.
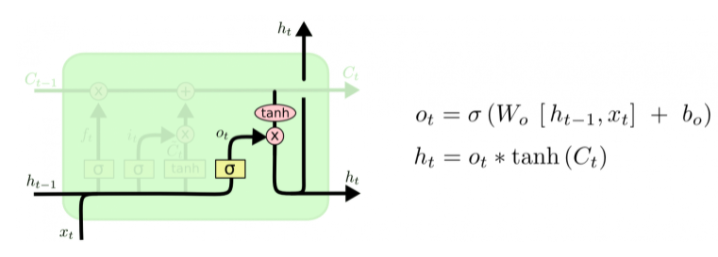
GRU
Gated Recurrent Unit - еще один вариант ячейки, очень похожий на LSTM, но с меньшим количеством фильтров (двумя), а значит и параметров. Помогает решить проблему , которая присуща обычным рекуррентным сетям.
Для решения проблемы затухающего градиента, GRU использует т.н. механизм, основанный на фильтрах обновления (update) и сброса (reset). Изначально имеется два вектора, которые решают, какая информация должна быть передана на выход. Их особенность в том, что их можно обучить сохранять информацию, поступившую далеко в прошлом, не забывая ее и избавляться от иррелевантной информации.
Рассмотрим ячейку GRU более подробно.
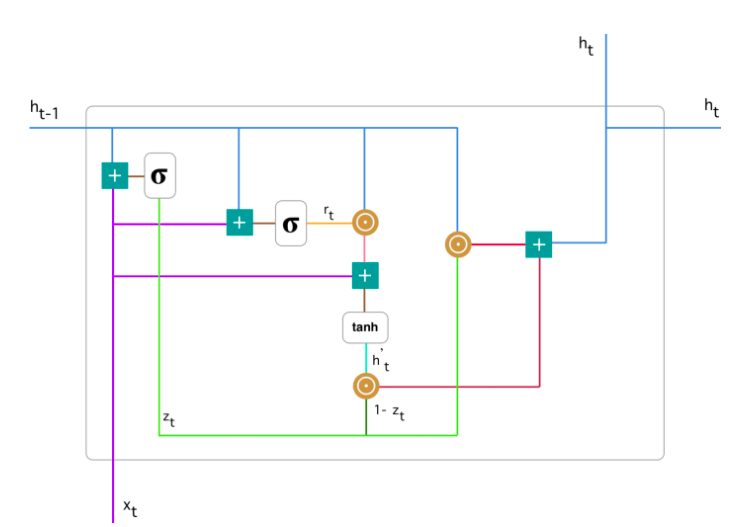
Базовые операции ячейки GRU:

Произведение Адамара - бинарная операция над двумя матрицами одинаковой размерности, результатом которой является матрица той же размерности, в которой каждый элемент с индексами \(i,j\) --- это произведение элементов с индексами \(i,j\) исходных матриц. Для двух матриц \(A,B\) одинаковой размерности \(m\times n\) произведение Адамара определено как покомпонентное произведение двух матриц:
Для двух матриц, которые имеют разные размерности, произведение Адамара не определено. Пример для матриц \(3\times 3\):
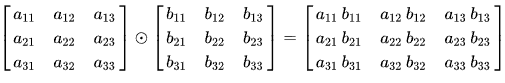
Фильтр обновления (Update Gate) - показывает, какое количество прошлой информации модель должна запомнить. Начинаем с вычисления фильтра обновления \(z_t\) в момент времени \(t\) по формуле: \(\(z_t = \sigma(W^{(z)}x_t+U^{(z)}h_{t-1})\)\)
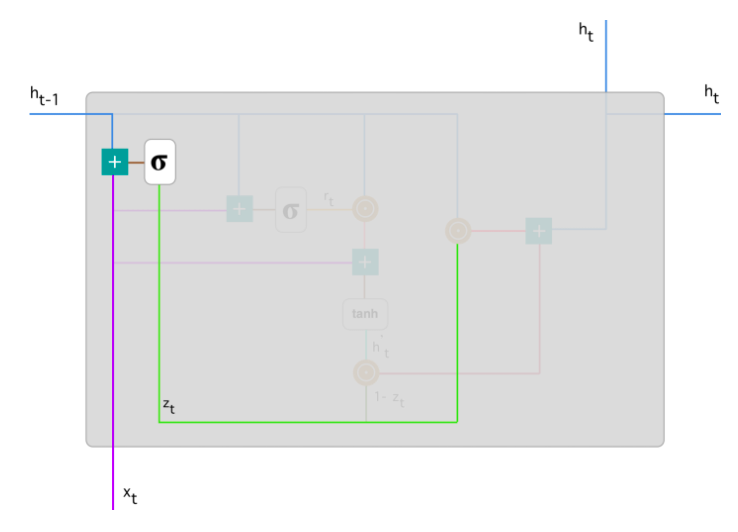
Когда \(x_t\) подается на вход ячейке сети, он умножается на соответствующий вес \(W^{(z)}\). Аналогично и для \(h_{(t-1)}\), который содержит информацию о предыдущих \(t-1\) элементах и умножается на соответствующий вес \(U^{(z)}\). Результаты складываются и применяется сигмоида, чтобы получить число между 0 и 1 - степень пропуска прошлой информации (полученной в предыдущие моменты времени) вперед, в будущее. Это работает, потому что модель может решить скопировать всю информацию (или большую ее часть) из прошлого и уменьшить риск возникновения затухающего градиента.\ Фильтр сброса (Reset Gate) - этот фильтр используется моделью для решения того, какое количество прошлой информации нужно забыть:
Данная формула аналогична формуле вычисления фильтра обновления. Различие лишь в том, какие веса используются для ее вычисления.
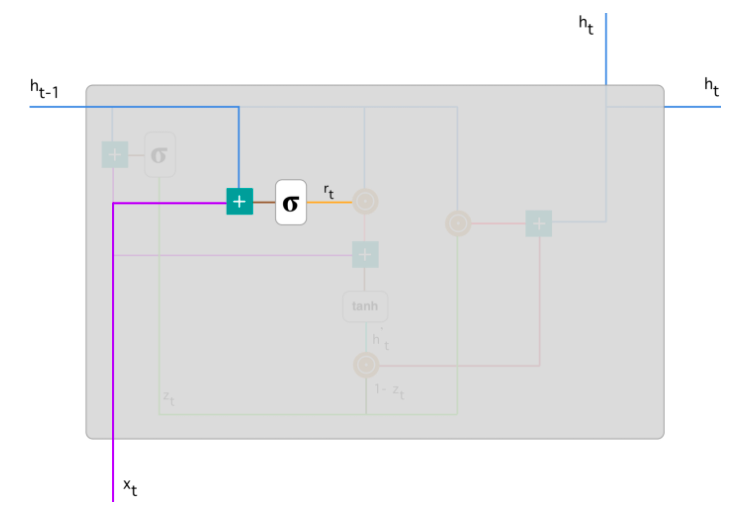
Текущее состояние памяти. Теперь рассмотрим, как эти два фильтра влияют на конечный выход ячейки. Начнем с фильтра сброса. Введем новое состояние памяти, которое будет использовать фильтр сбора для хранения релевантной информации из прошлого:
-
Перемножаем вход \(x_t\) на вес \(W\) и состояние \(h_{t-1}\) на вес \(U\).
-
Вычислим произведение Адамара (поэлементно) фильтра сброса \(r_t\) на \(Uh_{(t-1)}\). Таким образом определяется сколько нужно удалить информации с предыдущих шагов. К примеру, решается задача анализа тональности текста для определения мнения человека по поводу какой-либо книги. Текст начинается следующим образом: " Это фэнтези-книга, в которой описано..." и через несколько абзацев сказано следующее: "Мне не очень понравилась книга, потому что я думаю, что в ней слишком много деталей". Чтобы определить общий уровень удовлетворения книгой, нам необходима только последняя часть текста. В этом случае, по мере приближения к концу текста в процессе обучения сеть присвоит \(r_t\) близкое к нулю значение, забывая всю предыдущую информацию и фокусируясь только на последних предложениях.
-
Просуммировать п.1 и п.2
-
Применить нелинейную функцию активации - гиперболический тангенс.
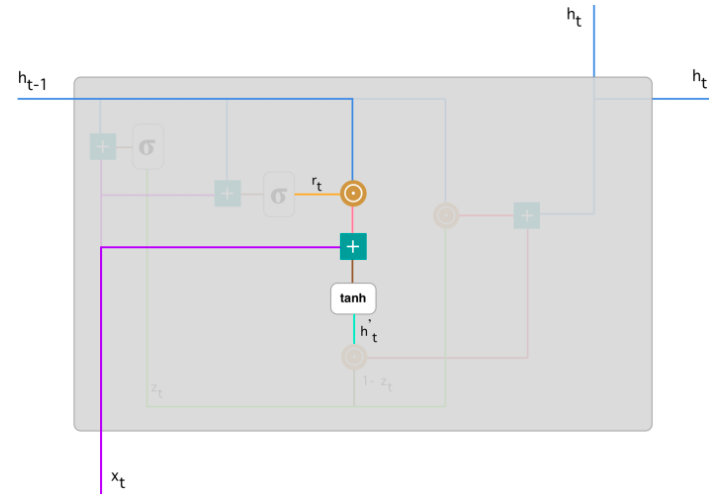
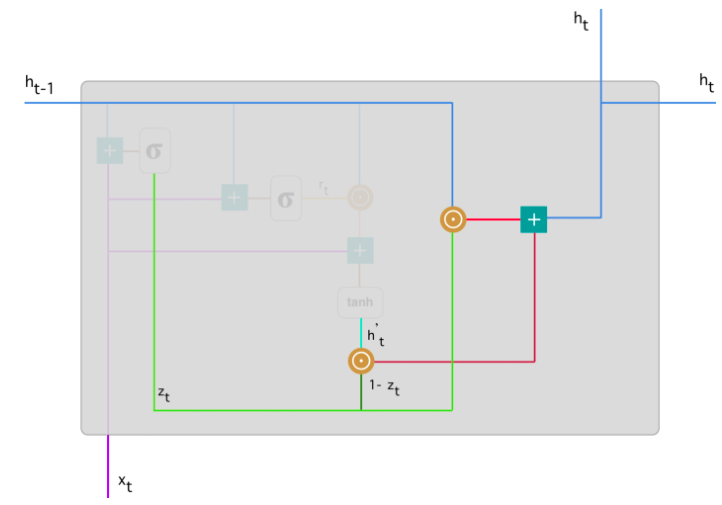
Финальное состояние памяти в текущий момент времени
В конце сети необходимо вычислить \(h_t\) - вектор, который содержит информацию от текущего элемента и передает ее вперед по сети. Для этого необходим фильтр обновления, который определяет, что взять из текущего состояния \(h^{'}_{t}\), а что из предыдущих шагов - \(h_{(t-1)}\):
Рассмотрим пример с книгой, только в этот раз самая релевантная информация расположена в начале текста. Модель в процессе обучения устанавливает значение \(z_t\), близкое к 1 и сохраняет большую часть предыдущей информации. Т.к. \(z_t\) будет близко к 1 в текущий момент времени, \((1-z_t)\) будет близко к 0, что позволит игнорировать большую часть текущей информации (в нашем случае, это конец текста), которая не актуальна для предсказания.
Взрыв градиента, затухание градиента
В процессе обратного распространения ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это в свою очередь может сделать нестабильным алгоритм обучения нейронной сети. В таком случае элементы градиента могут переполнить тип данных, в котором они хранятся. Такое явление называется взрывающимся градиентом (англ. exploding gradient).
Признаки, указывающие на взрывающийся градиент
-
Высокое значение функции потерь
-
Модель нестабильна, что отражается в значительных скачках значения функции потерь
-
Функция потерь принимает значение NaN
-
Веса модели растут экспоненциально
-
Веса модели принимают значение NaN
Существует аналогичная обратная проблема, когда в процессе обучения при обратном распространении ошибки через слои нейронной сети градиент становится все меньше. Это приводит к тому, что веса при обновлении изменяются на слишком малые значения, и обучение проходит неэффективно или останавливается, то есть алгоритм обучения не сходится. Это явление называется затухающим градиентом (англ. vanishing gradient).
Признаки, указывающие на затухающий градиент
-
Точность модели растет медленно
-
Градиент ближе к концу показывает более сильные изменения, в то время как градиент ближе к началу почти не показывает никакие изменения.
-
Веса модели уменьшаются экспоненциально во время обучения.
-
Веса модели растут экспоненциально
-
Веса модели стремятся к 0 во время обучения
Причины
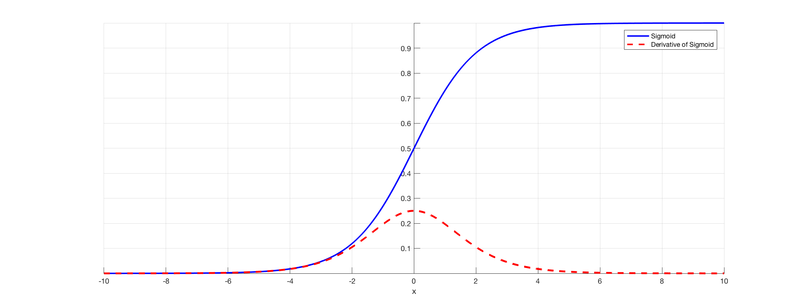
Такая проблема может возникнуть при использовании нейронных сетях классической функции активации - сигмоиды:
Эта функция часто используется, поскольку множество ее возможных значений --- отрезок \([0,1]\) --- совпадает с возможными значениями вероятностной меры, что делает более удобным ее предсказание.
Пусть сеть состоит из подряд идущих нейронов с функцией активации \(\sigma(x)\)
-
функция потерь \(L(y)=MSE(y,\overline{y} )=(y−\overline{y})^2\)
-
\(u_d\) --- значение, поступающее на вход нейрону на слое \(d\)
-
\(w_d\) --- вес нейрона на слое \(d\)
-
\(y\) --- выход из последнего слоя
Оценим частные производные по весам такой нейронной сети на каждом слое. Оценка для производной сигмоиды видна из рисунка.
и т.д.
Откуда видно, что оценка элементов градиента растет экспоненциально при рассмотрении частных производных по весам слоев в направлении входа в нейронную сеть (уменьшения номера слоя). Это в свою очередь может приводить либо к экспоненциальному росту градиента от слоя к слою, когда входные значения нейронов --- числа, по модулю большие 1, либо к затуханию, когда эти значения --- числа, по модулю меньшие 1.
В частности, сигмоида насыщается при стремлении аргумента к \(+\infty\) или \(-\infty\), то есть имеет там конечный предел. Это приводит к тому, что более отдаленные слои обучаются медленнее, так как увеличение или уменьшение аргумента насыщенной функции вносит малые изменения, и градиент становится все меньше. Это и есть проблема затухающего градиента.
Способы устранения
-
Использование другой функции активации
-
Изменение модели - сокращение числа слоев. Это связано с тем, что частные производные по весам растут экспоненциально в зависимости от глубины слоя. В рекуррентных нейронных сетях можно воспользоваться техникой обрезания обратного распространения ошибки по времени, которая заключается в обновлении весов с определенной периодичностью.
-
Использование
-
Регуляризация весов
Градиентный клиппинг
Обрезание заключается в ограничении нормы градиента. То есть если норма градиента превышает заранее выбранную величину \(T\), то следует масштабировать его так, чтобы его норма равнялась этой величине:
Механизм внимания. Self-Attention, Multi-head-attention. Маскированное внимание. Архитектура трансформер и использование механизма внимания в ней. Современные языковые модели: двунаправленные энкодеры (BERT), генеративные трансформеры (GPT).
Рассмотрим задачу машинного перевода, т.е. нам нужно перевести фрагмент текста с одного языка на другой, например, с английского на русский. Подход, используемый в нейросетевой архитектуре для машинного перевода называется sequence-to-sequence (seq2seq).
Простейшая нейросетевая архитектура
Encoder-Decoder архитектура состоит из \(2\)-ух RNN сетей
-
Первая -- рекуррентная нейронная сеть. Как мы помним, каждое следующее скрытое состояние обусловлено на все предыдущие, то есть на весь левый контекст. Поэтому последний синий вектор для слова\ textit"great" кодирует весь текст, который мы подали на вход нашей архитектуре. Так давайте тогда возьмем этот вектор и воспользуемся им как закодированной информацией той фразы, которую мы хотим перевести -- передадим его в декодер (зеленая сеть).
-
Вторая -- рекуррентная нейронная сеть. Ей в начало приходит скрытое состояние - закодированная фраза из предыдущего пункта и \<SOS> (Start of sequence) токен. Далее мы генерируем слово и передаём его на вход следующего этапа. Таким образом мы разворачиваем закодированный вектор из енкодера и получаем требуемый перевод.
Часто сначала учат генерировать текст энкодер и декодер на соответствующих языках по отдельности. Потом соединяют их как тут и дообучают под перевод.
Причём все это обучается end-to-end. На рисунке. Нужен только размеченный датасет с переводами, что не проблема, так как много уже переведенных текстов, например, можно взять "Войну и Мир" на русском и английском языке.
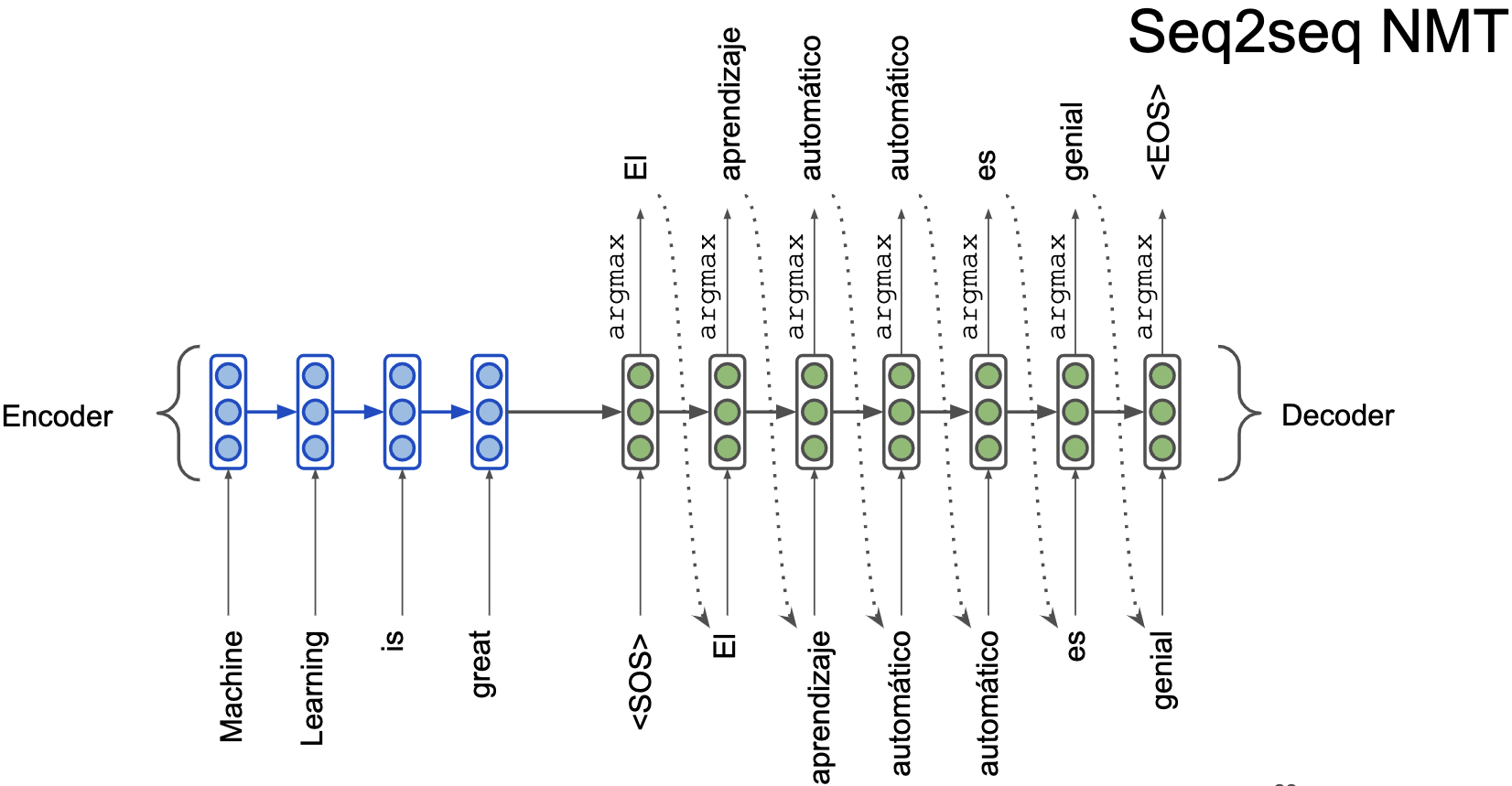
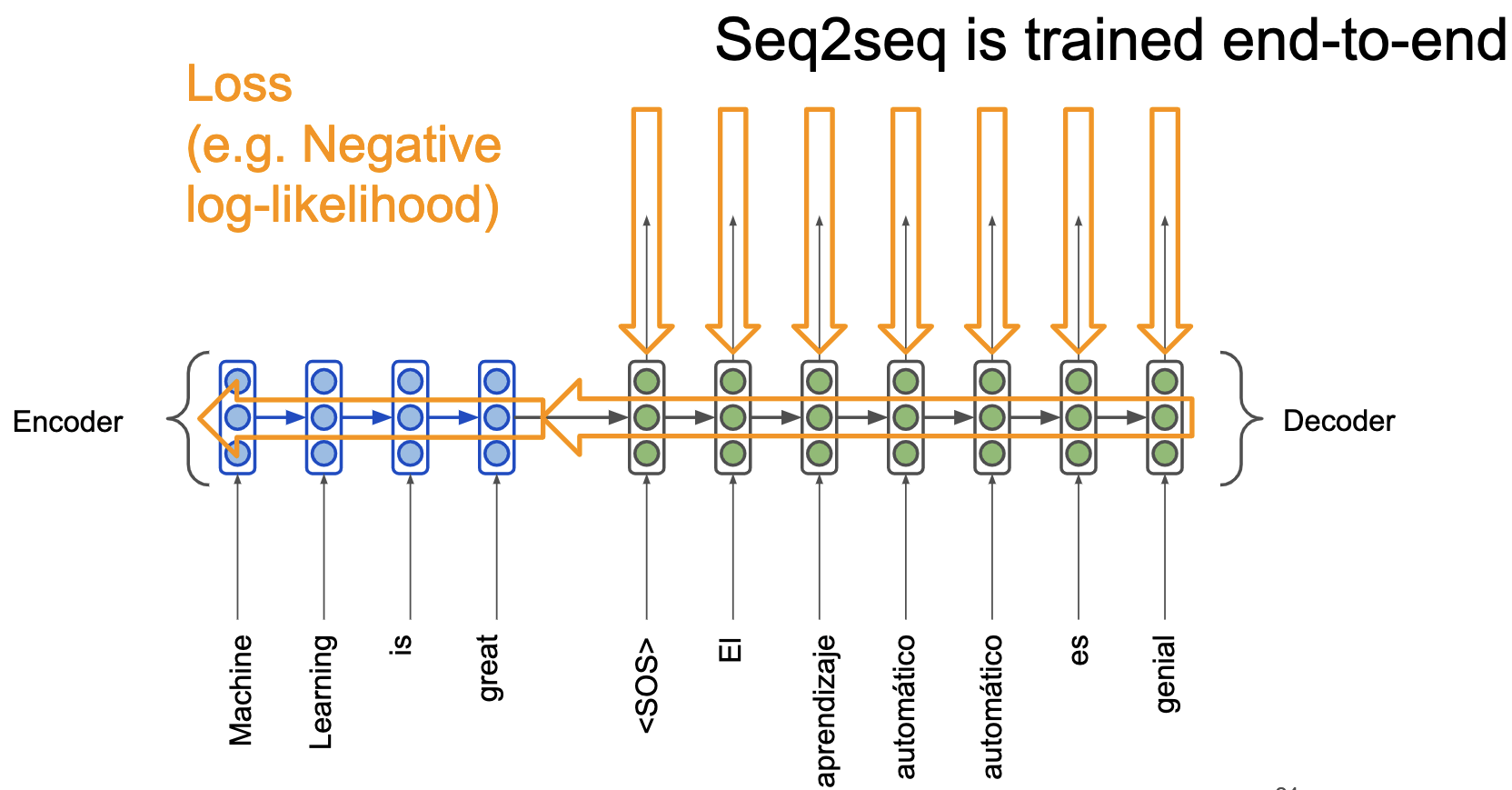
Механизм внимания. Attention
Проблема предыдущего подхода заключается в том, что декодер обуславливается на состояние, кодирующее весь входной текст. Если входной текст будет достаточно большой, то его embedding будет малоинформативным.
Вспомним, как мы переводим предложения с одного языка на другой -- мы пытаемся построить некоторое отображение слов предложения в слова другого языка с учётом правил грамматики. Мы обращаем внимание на то, какое слово из предложения мы сейчас переводим.
Давайте ровно так же, при переводе каждого следующего слова будем обращать внимание на слова исходной фразы, причём большее внимание обращать на то слово, которое пытаемся перевести прямо сейчас.
-
Обозначим скрытые состояния (hidden states) энкодера как \(\mathbf{h}_1, \mathbf{h}_2, \dots \mathbf{h}_N \in \mathbb{R}^k\).
-
Обозначим скрытое состояние (hidden states) декодера в момент времени \(t\) как \(s_t \in \mathbb{R}^k\).
-
Тогда мы можем вычислить то, насколько текущее слово, которое мы пытаемся перевести похоже на слова из входного текста. Для этого мы можем вычислить некоторую меру сходства между \(s_t\) и каждым из \(\mathbf{h}_1, \mathbf{h}_2, \dots \mathbf{h}_N\), например, вычислив скалярное произведение между векторами. Вычисленные меры сходства называются attention scores. Обозначим полученный вектор сходств как \(e_t = [s_t^T\mathbf{h}_1, \dots s_t^T\mathbf{h}_N]\).
-
Нам привычнее работать с вероятностями, поэтому возьмем softmax от attention scores \(e_t\) и получим attention distribution vector \(\alpha_t = softmax(e_t)\).
-
А теперь давайте агрегируем все векторы входных слов с весами, полученные из attention distribution vector: \(\mathbf{a}_t = \displaystyle\sum_{i=1}^{N}\alpha_{t, i}\mathbf{h}_i \in \mathbb{R}^k\). А затем приконкатенируем его к текущему скрытому состоянию переводимого слова \(s_t\), чтобы мы могли обуславливаться на входные слова с учетом внимания.
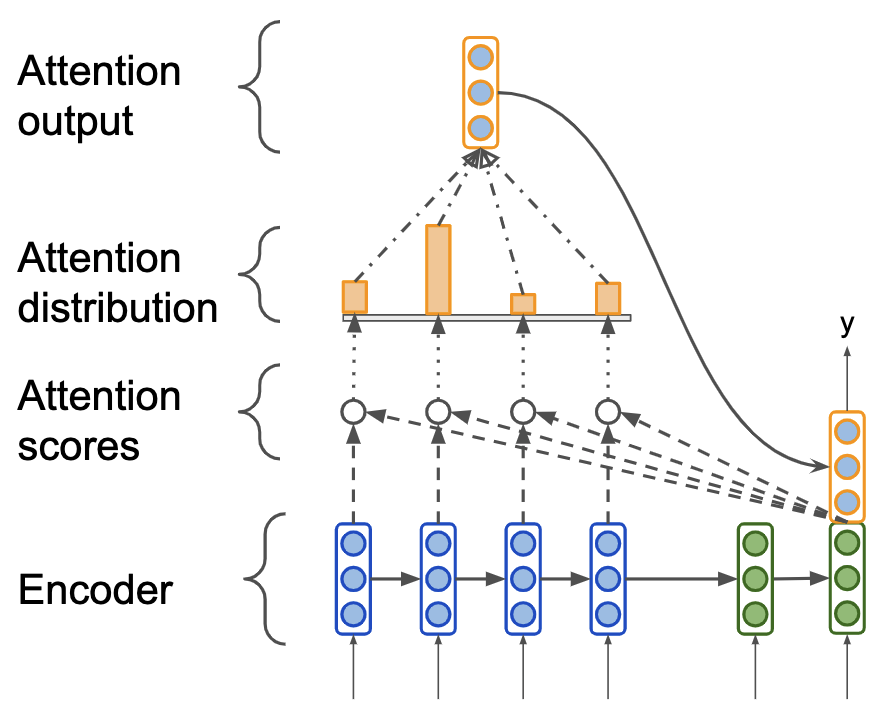 |
|---|
| Механизм внимания при переводе следующего слова. |
Self-Attention
Идея с механизмом внимания в рекуррентных сетях крутая. А можно ли без рекуррентных сетей?
Self-Attention -- механизм, который используется для того, чтобы находить значимость любых элементов последовательности друг для друга. Для примера, рассмотрим предложение "The animal didn't cross the street because it was too tired".
 |
|---|
| Self-Attention позволяет находить значимость любых элементов последовательности друг для друга. |
Стоит обратить внимание на то, что у нас есть некоторая "направленность". То есть когда мы говорим о значимости связи \(\text{element}_1\text{ и element}_2\), это не то же самое, что и связь \(\text{element}_2\text{ и element}_1\). Для того чтобы различать эти случаи, введем направление для каждого элемента последовательности с помощью двух векторов: [query]{style="color: mypurpur"} -- откуда и [key]{style="color: myorange"} -- куда. Кроме того для каждого элемента введём вектор [value]{style="color: myblue"}, который будем обозначать смысл слова в отрыве от контекста, самого по себе.
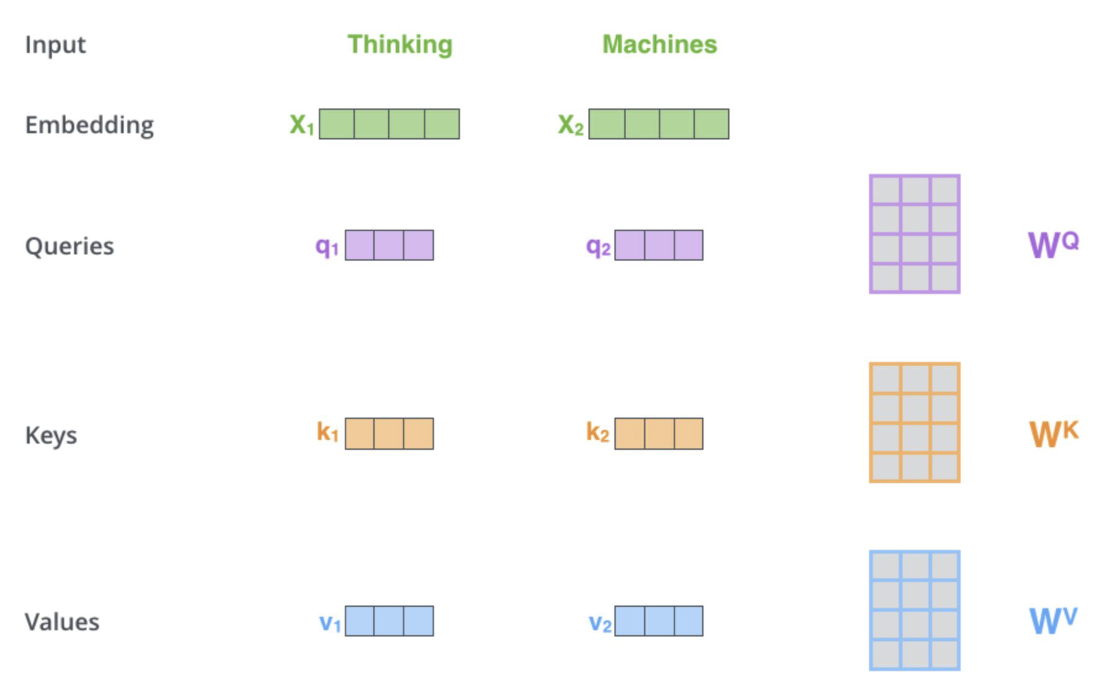 |
|---|
| Self-Attention. У каждого слова есть его embedding, мы тренируем три матрицы [\(W^Q\)], [\(W^K\)], [\(W^V\)], чтобы умножая на них вектор embedding мы переходили в пространства, с векторами [query], [key], [value] |
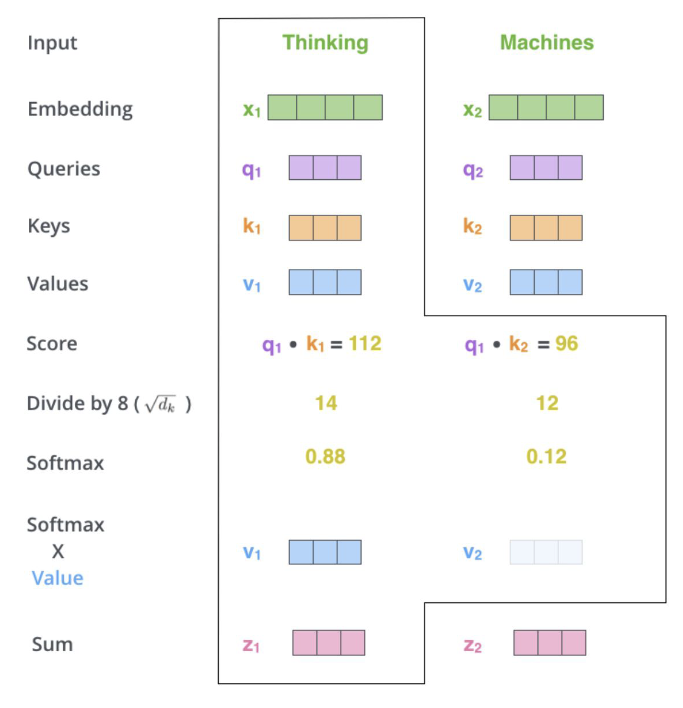 |
|---|
| Self-Attention. Вычисляем score как скалярное произведение [query] текущего слова и [key] другого, нормализуем, берем софтмакс, [value] вектор, суммируем по всем таким результатам с [key] других векторов, получаем новый вектор z для каждого элемента последовательности. Это результат Self-Attention слоя. |
Multi-head-attention
Multi-head-attention -- это много Self-Attention (как много фильтров в свертках), каждая из голов может выполняться параллельно, в чем большое преимущество над RNN. Зачем? -- между словами можно пытаться уловить зависимости разного рода, каждую из таких зависимостей будет пытаться уловить свой Self-Attention.

Трансформер
| Архитектура трансформер. |
| Архитектура трансформер. Энкодер внутри себя включает Self-Attention и полносвязный слой с нелинейностью. |
Декодер в трансформере очень похож на энкодер, но только в нём используются key и value из энкодера, а query из самого декодера, это нужно для того, чтобы использовать внимание как в seq2seq модели с двумя RNN.
| Архитектура трансформер. Декодер. |
Кроме того используется маскирование, для того, чтобы декодер не подглядывал на все предложение, а считал внимание только на текущей обработанной части фразы. Для этого зануляются вектора тех элементов, до которых декодер ещё не дошел на этой итерации.
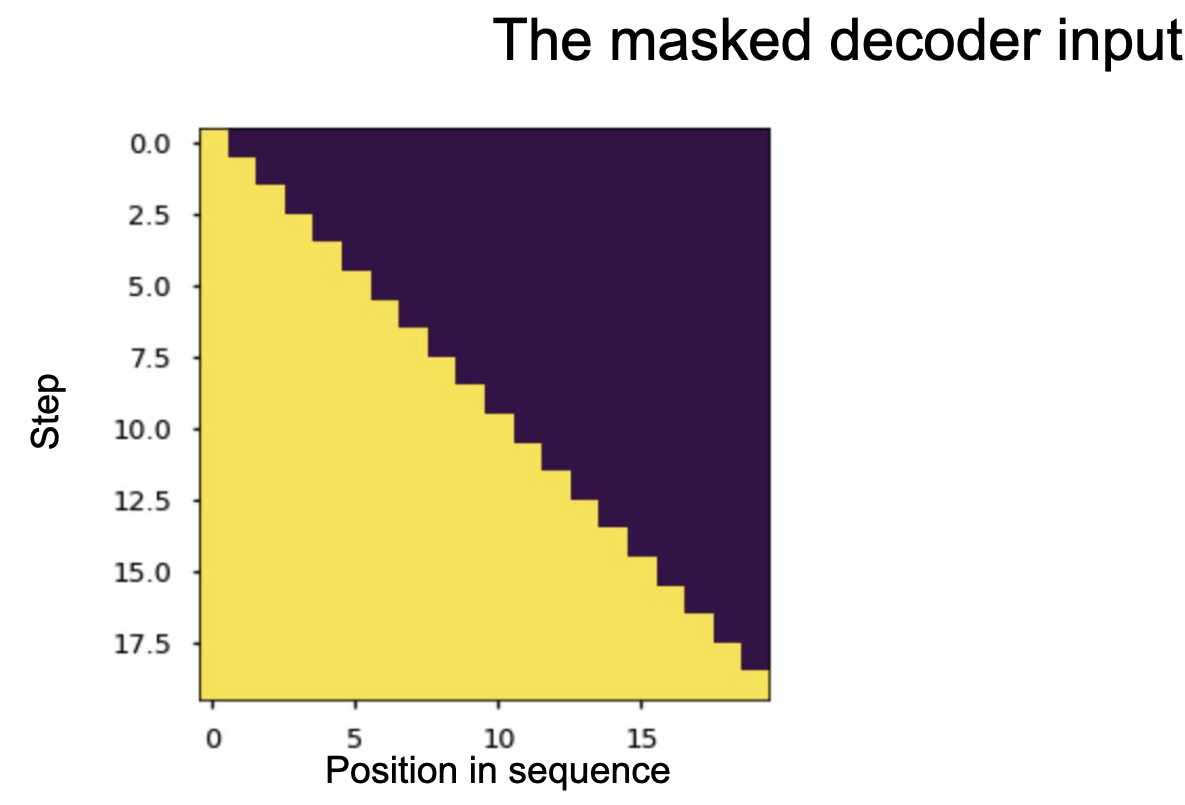 |
|---|
| Маскирование в декодере. |
BERT
Взяли энкодер часть из трансформера, добавили несколько модификаций и назвали это дело BERT-ом. [CLS] токен в начале, в нём по результатам будет все скрытое представление входного текста. Далее маскируем один токен из на входе [MASK], и пытаемся предсказать его на выходе. Таким образом производим обучение.
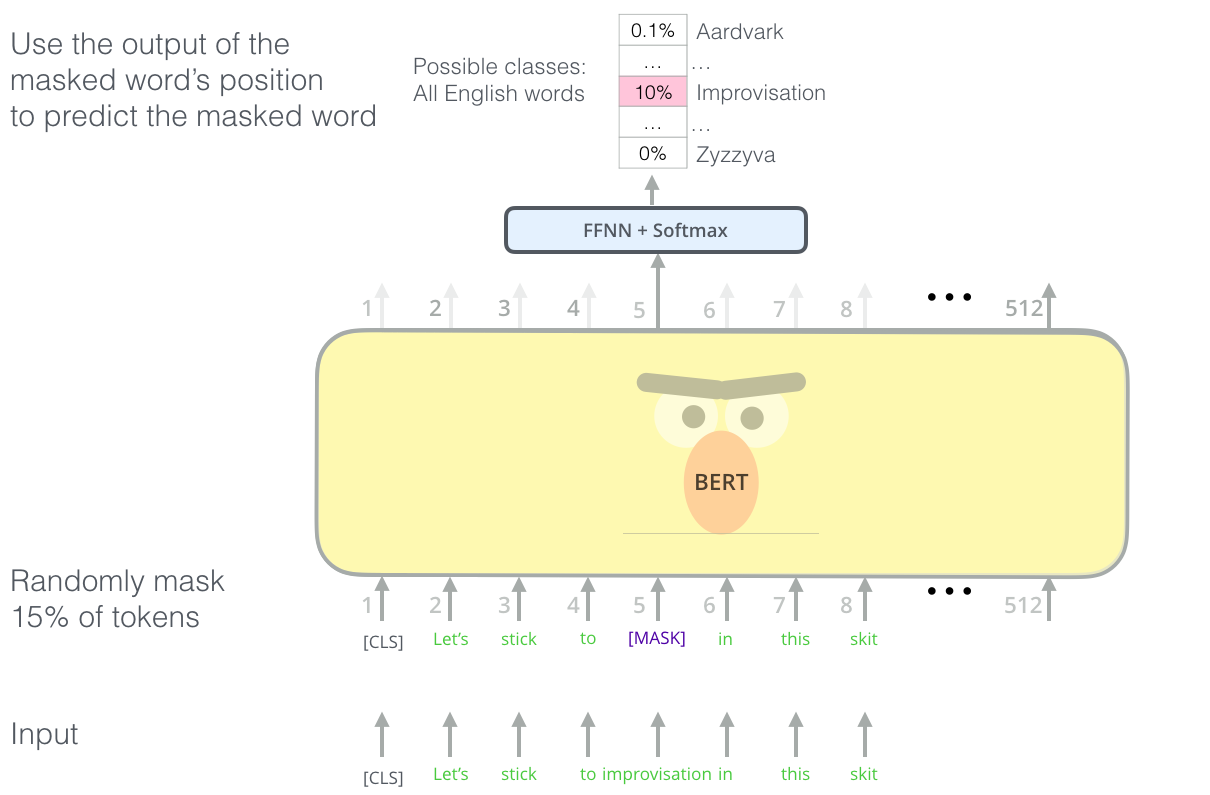 |
|---|
| BERT. Прдсказывание [MASK] слова |
Можно еще предсказывать, что одно слово за другим по смыслу или нет:
 |
|---|
| BERT. Предсказывание предложения одно за другим или нет |
| BERT. Transfer Learning. Можно сначала учить на большом корпусе решать общую задачу, а затем дообучаться под подзадачу, в том числе используя [CLS] токен. |
GPT
-
GPT-2 появился параллельно с BERT примерно.
-
Основан на декодере трансформера.
-
Обучим его просто предсказывать следующее слово.
-
GPT-2 на 1.5 миллиарда параметров, а GPT-3 на 150 миллиардов параметров.
-
Обучим на огромном массиве данных (8 миллионов веб-страниц для GPT-2)
| GPT-2 это декодер трансформера, а BERT это энкодер трансформера. |